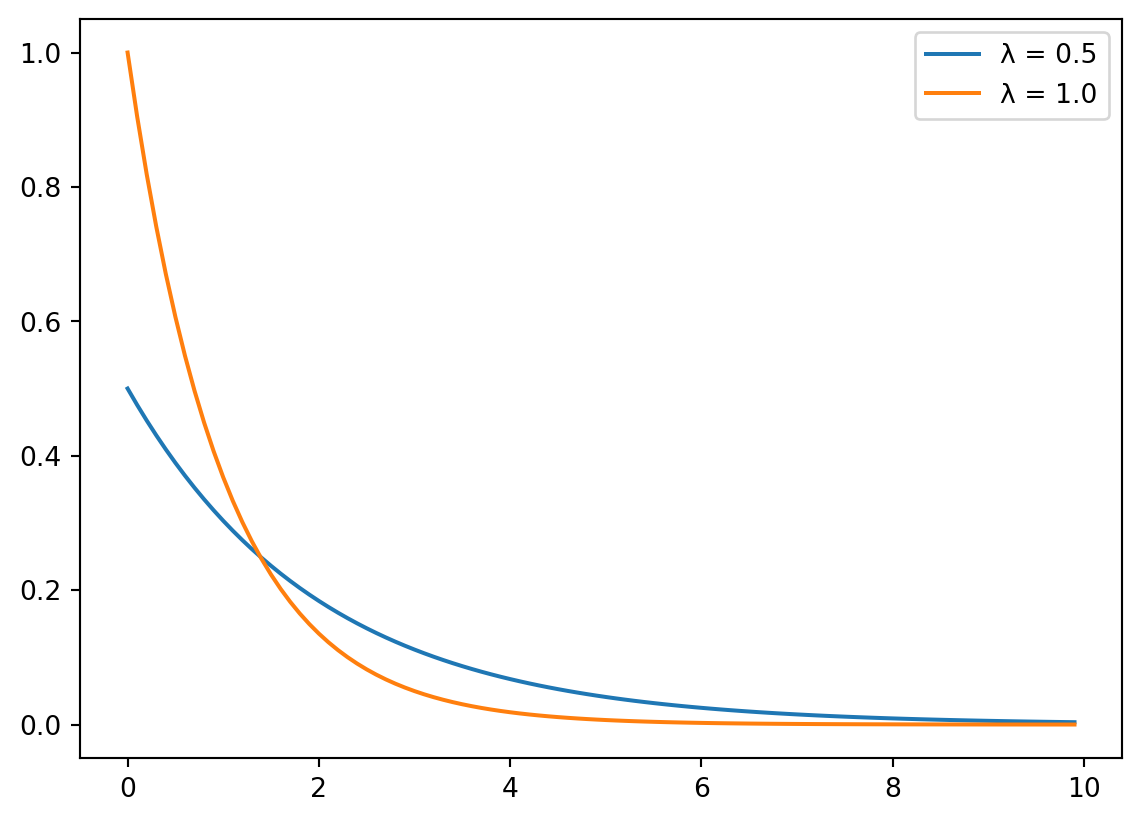
Suppose buses arrive at a bus stop according to an exponential distribution with rate λ = 0.5 per minute. This means the average waiting time is 1/λ = 2 minutes.
(A) Write Python code using scipy.stats.expon to plot the PDF of the exponential distribution with rate λ = 0.5. On the same plot, add the PDF for an exponential distribution with rate λ = 1.0 (scale = 1).
import scipy.stats as stimport matplotlib.pyplot as pltimport numpy as npx = np.arange(0,10,0.1)y = st.expon.pdf(x, scale =1/0.5)plt.close()plt.plot(x,y, label ="λ = 0.5")y2 = st.expon.pdf(x, scale =1/1)plt.plot(x,y2, label ="λ = 1.0")plt.legend()
Q7 The probability density function for a normal distribution is:
(B) Generate N=100 values from a Normal(50, 10) distribution. What proportion of your sample falls within one standard deviation of the mean (between 40 and 60)?
y = st.norm.rvs(loc=50,scale=10,size=100,random_state =1)observed_proportion = ((40< y) & (y <=60)).mean()print(observed_proportion)
0.76
(C) The theoretical proportion is 68%. Calculate the simulation error (absolute difference).
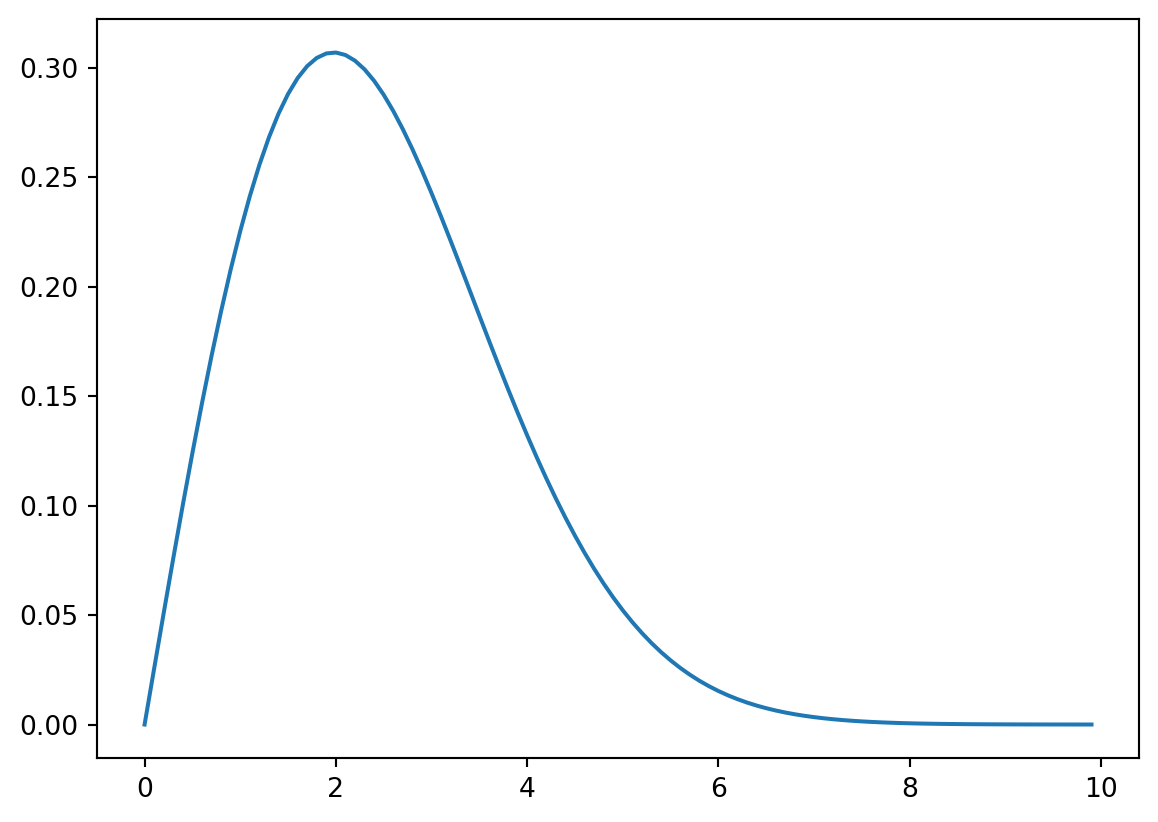
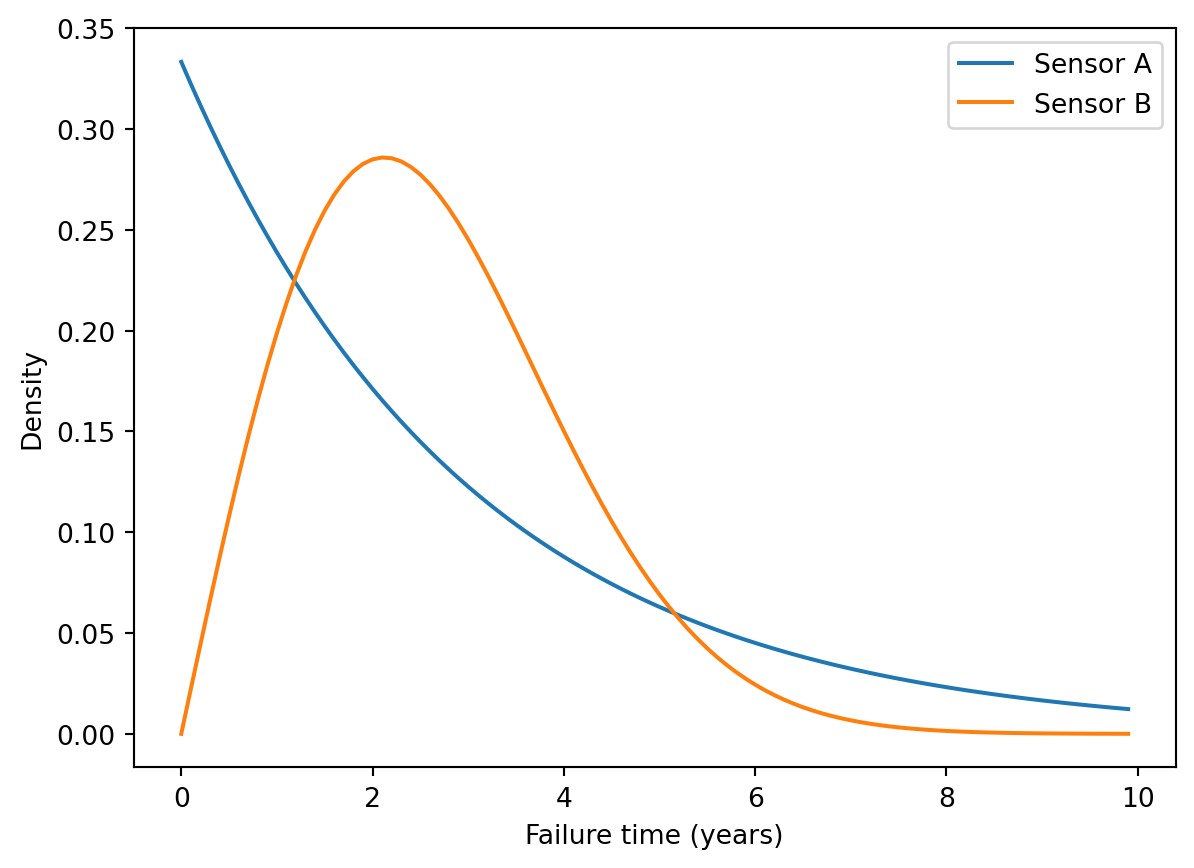
Q18 Consider a system composed of two sensors, A and B, in sequence.
The system fails when either A or B fails. The failure time for sensor A follows an exponetial distribution with mean failure time of 3 years. The failure time for sensor B follows a Weibull distrubtion with scale = 3 and shape = 2.
import scipy.stats as stimport matplotlib.pyplot as pltimport numpy as npxx = np.arange(0,10,0.1)zz = st.expon.pdf(xx,scale=3)yy = st.weibull_min.pdf(xx, c =2, scale =3)plt.close()plt.plot(xx,zz, label ="Sensor A")plt.plot(xx,yy, label ="Sensor B")plt.xlabel("Failure time (years)")plt.ylabel("Density")plt.legend()
If \(A_F\) and \(B_F\) are the failure times of sensors \(A\) and \(B\), then the failure time of the entire system, denoted by \(S_F\) is
\[
S_F = \min\left(A_F, B_F\right)
\]
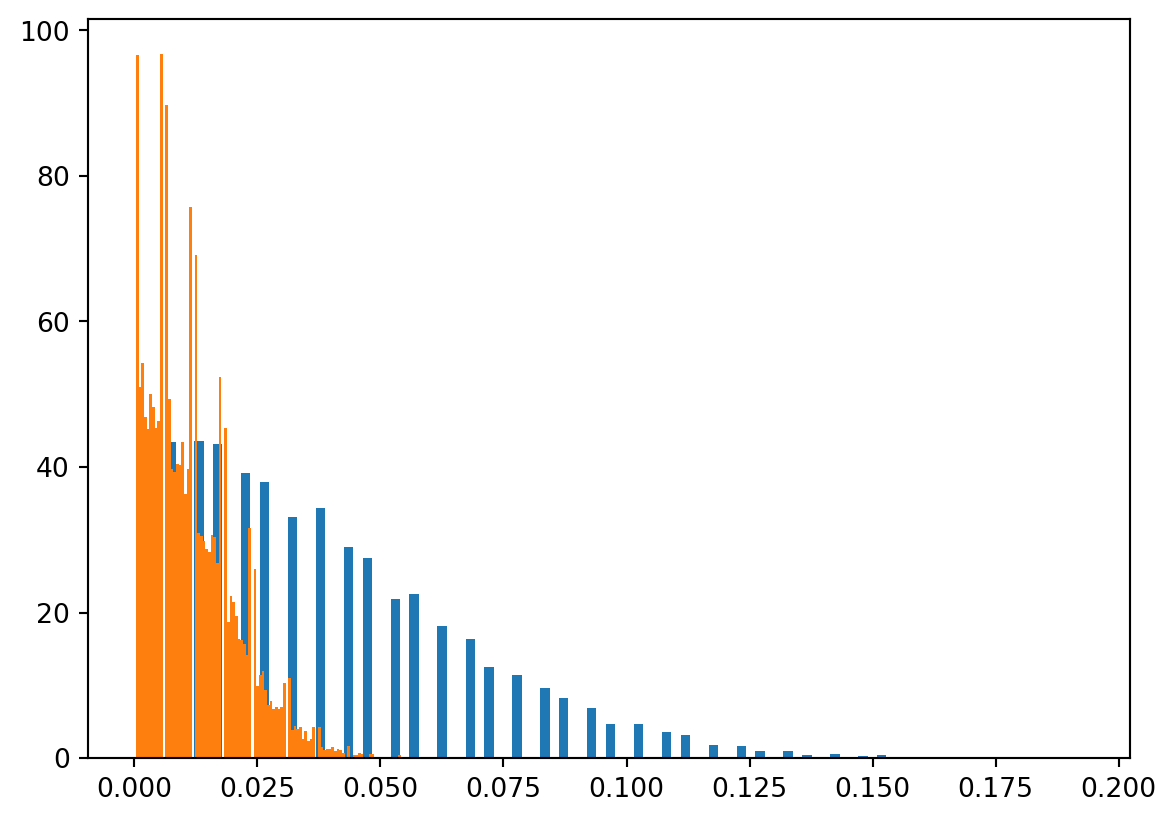
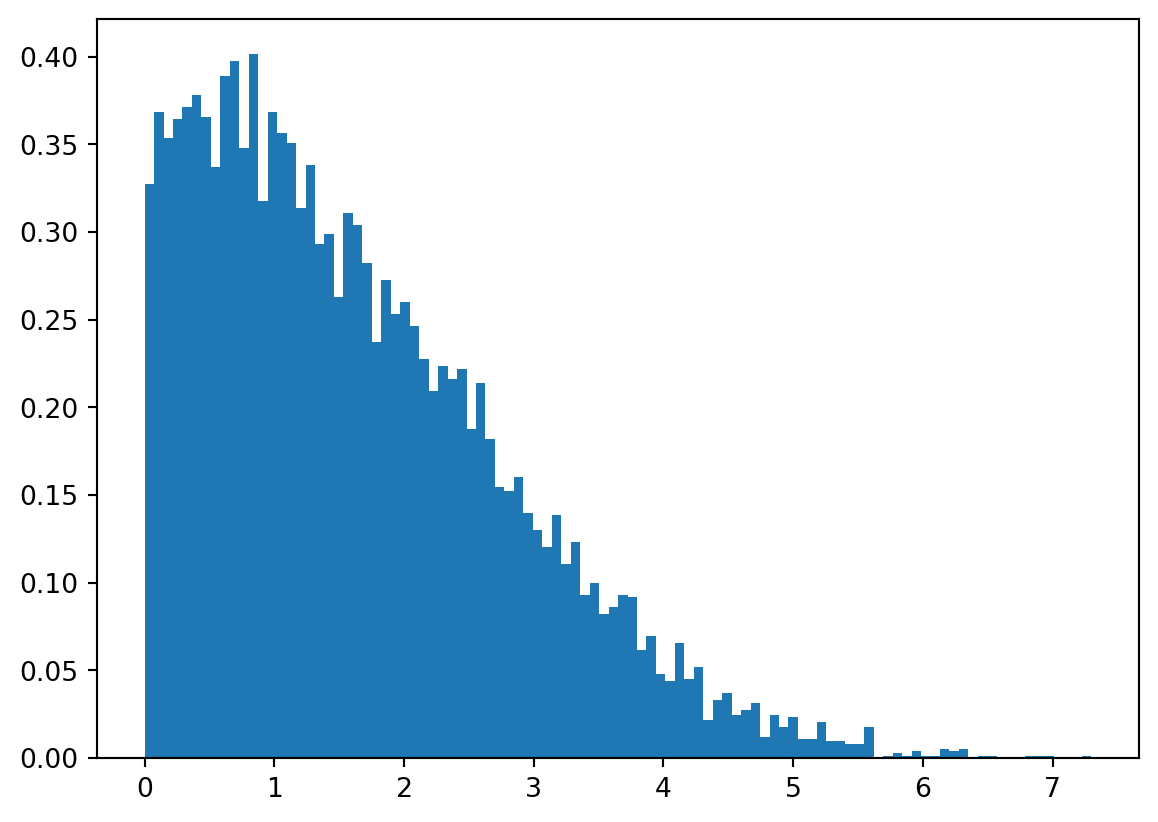
We can simulate the distrubtion of \(S_F\) and its properties like mean, median, and variance.
R =10000AF = st.expon.rvs(size=R,scale=3)BF = st.weibull_min.rvs(size=R, c =2, scale =3)SF = np.minimum(AF, BF)plt.close()plt.hist(SF, density =True,bins=100)Summary = {"Mean":f"{SF.mean().item():.2f} (years)" , "Median":f"{np.median(SF).item():.2f} (years)" , "SD":f"{np.std(SF).item():.2f} (years)" , "Var":f"{np.var(SF).item():.2f} (years^2)"}import pandas as pdsum1 = pd.DataFrame.from_dict(Summary, orient ="index", columns= ["Initial"])sum1
Initial
Mean
1.64 (years)
Median
1.41 (years)
SD
1.19 (years)
Var
1.42 (years^2)
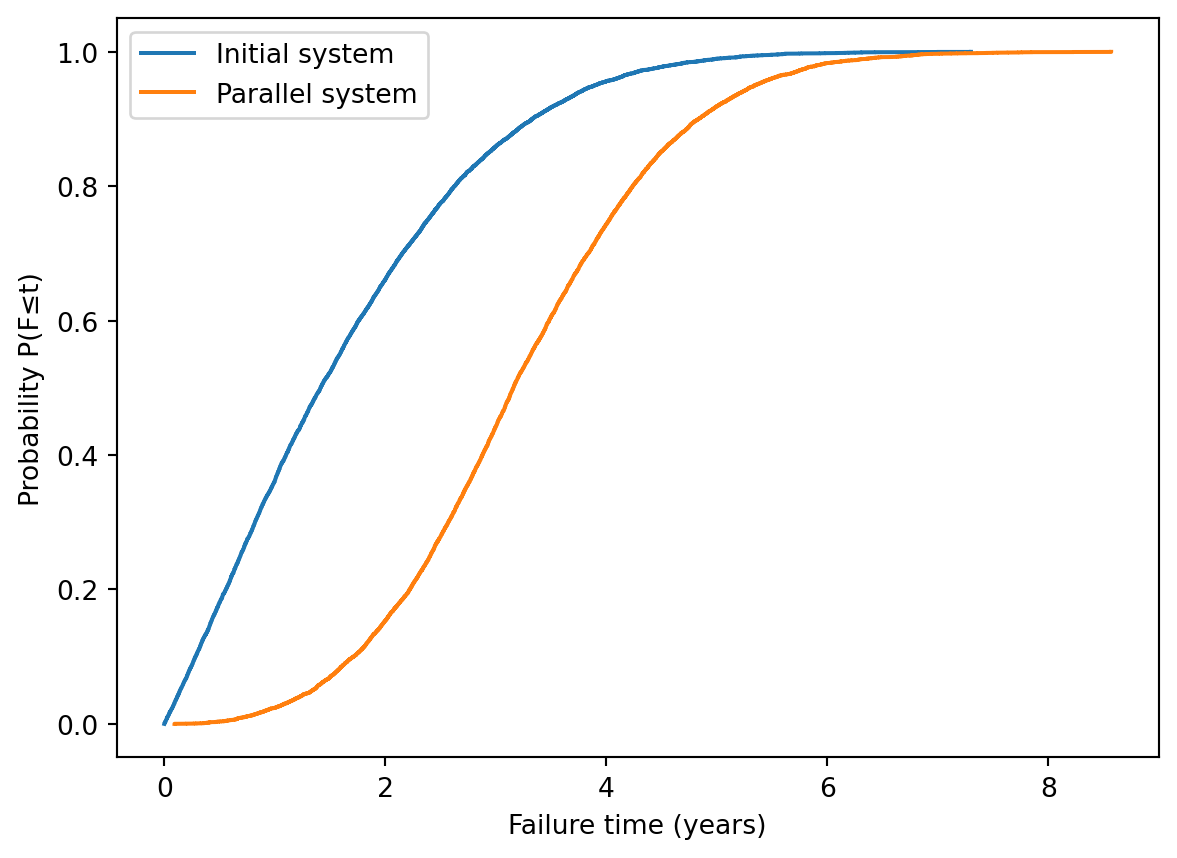
Consider an improvement of the system, in which additional sensors are added in parallel.
The new system fails either when all of the A sensors fail or when all of the B sensors fail. The failure time of the sensors are all independent.
(A) Using simulation, generate a density estimate of the failure time for the improved system using the histogram. (Compare it to the previous distribution by placing the histograms of the old and new systems in the same plot.)
(B) Add another column to the table of summary measures for the improved system.
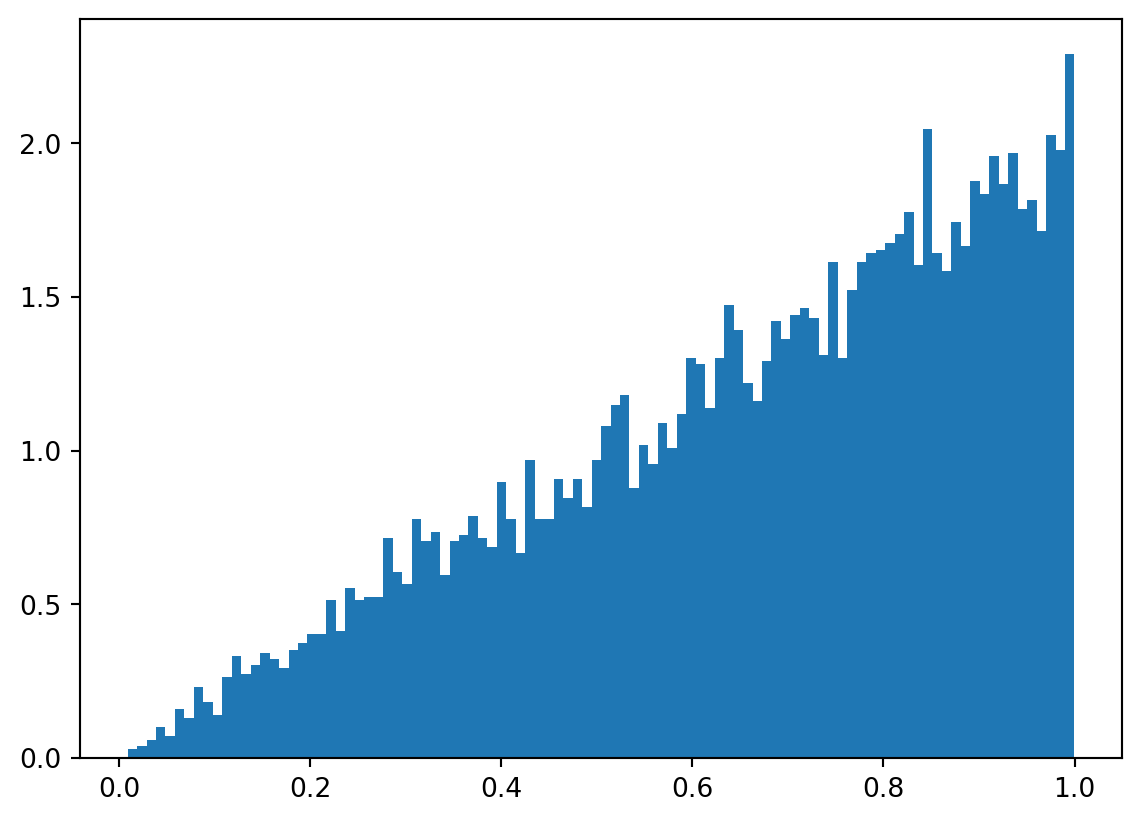
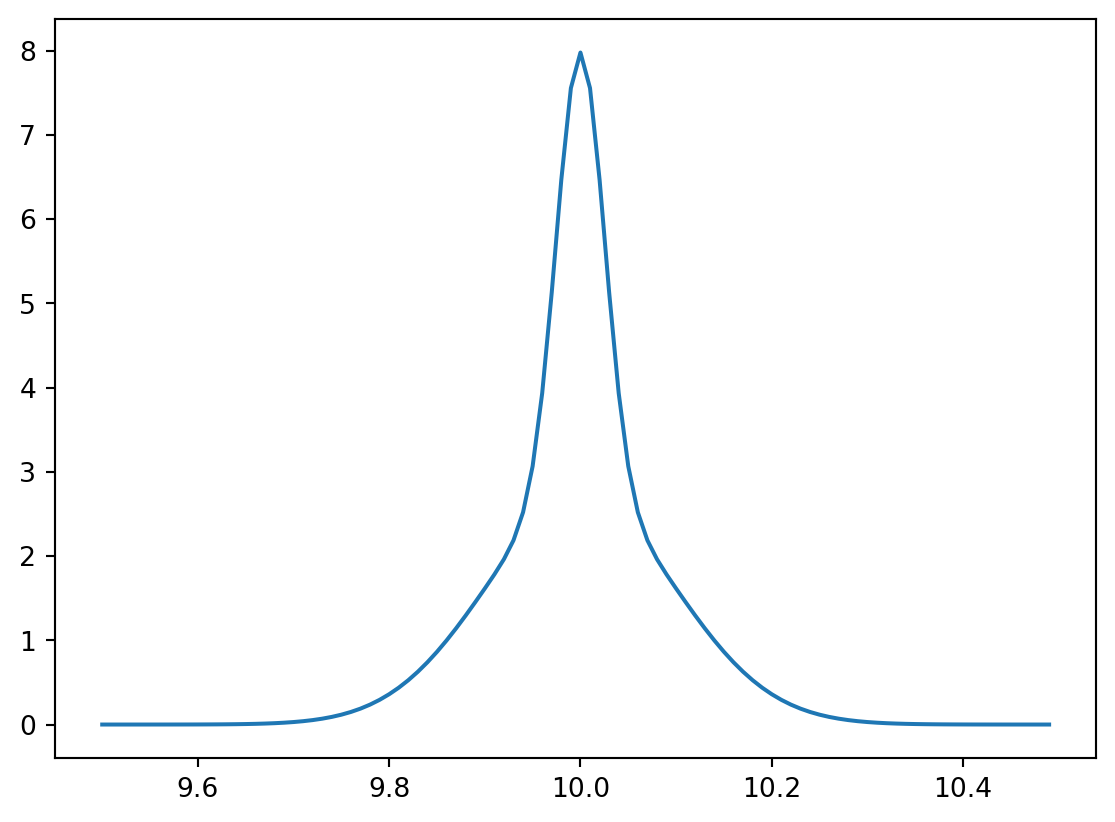
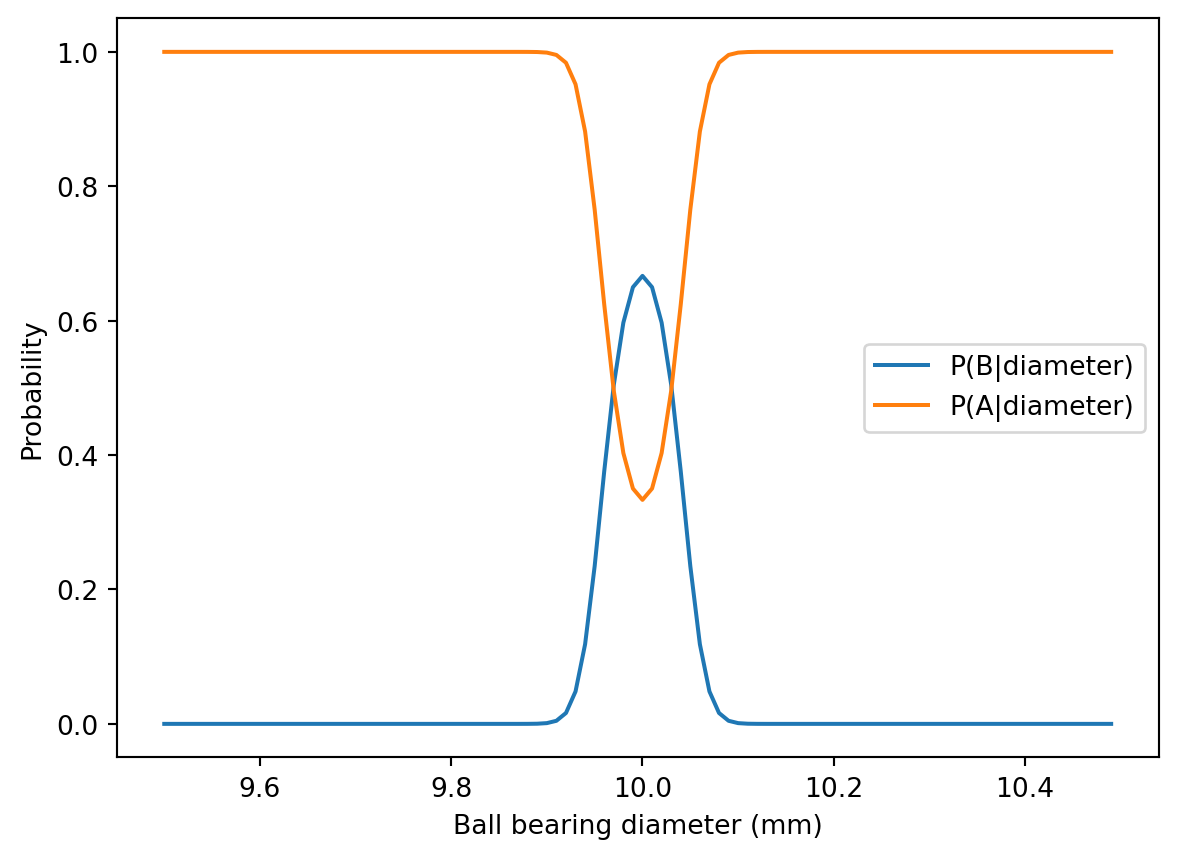
Q19 Ball bearings from machine A have diameters which follow a normal distribution with mean 10 and standard deviation 0.1. Machine B is more precise and generates ball bearings with the same mean but with a smaller standard deviation of 0.025. The additional precision comes at a cost: for every 1 ball bearing generated by machine B, machine A is able to produce 2 bearings.
(A) Generate a plot of the marginal density of ball bearing diameters generated at the factory. (The factory only has machines A and B.)
xx = np.arange(9.5,10.5,0.01)ay = st.norm.pdf(xx, loc =10, scale =0.1)by = st.norm.pdf(xx, loc =10, scale =0.025)yy =2/3*ay +1/3*byplt.close()plt.plot(xx,yy)
(B) Calculate the probability that a randomly selected ball bearing came from machine B given that its diameter is 9.9.
Q20 The Monte Hall problem is a classic game show. Contestants on the show where shown three doors. Behind one randomly selected door was a sportscar; behind the other doors were goats.
At the start of the game, contestants would select a door, say door A. Then, the host would open either door B or C to reveal a goat. At that point in the game, the host would ask the contestant if she would like to change her door selection. Once a contestant decided to stay or change, the host would open the chosen door to reveal the game prize, either a goat or a car.
Consider two strategies:
Always stay with the first door selected.
Always switch to the unopened door.
(A) Use simulation to determine the probability that each strategy wins the sportscar. The following code will simulate a single game. You may want to tweak it so that it generates results for R replicates.
The “stay” strategy wins 1/3 of games. The “switch” strategy wins the remaining 2/3 or games. (Note, with 3 doors, one of the strategies must win each game.)
(B) Modify the code so that it works for a game with \(N\) doors. Calculate the probability of winning for each strategy with \(N=4\).